Contest Problems
1. Introduction
AI democratization accelerates the process of applying machine learning techniques (i.e., neural networks) in broad medical fields, among which dermatology has taken the pole position due to the maturity of the existing skin lesion datasets. Unlike natural images (e.g., ImageNet [1]), however, bias is commonly existing in the skin lesion datasets, which is caused by the imbalance of data in terms of skin tones. Founder and CEO of First Derm, Alexander B ̈orve, admits that images of black skin only make up about 5-10% of the company’s database, and even less for skin tones from other minority groups such as Asian and Hispanic. That is a red flag for applying machine learning (ML) in dermatology because it can easily lead the trained neural network to have a looks-good overall accuracy but extremely low accuracy for certain groups. This may lead to accidents in autonomous driving, linguistic discrimination in language translation, and even threatening life by misdiagnosis in healthcare.
AI models have been deployed in an increasing number of platforms, from mobile dermatology assistants, mobile eye cancer (leukoria) detection, emotion detection, comprehensive vital signs monitoring, and childhood welfare systems, to medical imaging and diagnostics. This competition invites teams to address this challenge from an angle - achieve fairness, accuracy, and latency on edge devices at the same time. Dermatology images are used for evaluation.
2. Objective
The goal of the 2023 ESWEEK Fairness Competition Track is to achieve fairness, accuracy, and latency for the hardware platform from the dermatology dataset.
We ask participants to design and implement a working, open-source AI/ML algorithm that can automatically discriminate skin disease from skin image while being able to be deployed and run on the given platform [2]. We will award prizes to the teams with top comprehensive performances in terms of detection accuracy, fairness, and inference latency.
3. Data
The data contains images of different diseases and it can also be divided into several subgroups regarding skin tones(i.e., white skin). Each image shows skin suffering from a certain type of skin disease, and each image has additional labels, such as skin color. Here, for the classification of disease, it contains the disease labels including BCC, DF, MEL, NV, SCC, and NV, We will provide the lists of labels for reference. The dataset is partitioned patient-wisely in the training and testing set. 80% of the images are released as training material. The rest 20% will be utilized to evaluate the detection performances of the submitted algorithm. The dataset for final evaluation will remain private and will not be released.
4. Platform
Raspberry Pi [3] boards are tiny, incredibly versatile computers that have been put to an increasing number of practical, fun, and diverse uses by hobbyists. This exceptional flexibility has only been increased over the years by manufacturers coming out with a plethora of add-ons like sensors, touchscreens, wireless connectivity modules, and purpose-built cases. This latest main-line generation from the Raspberry Pi Project includes the Raspberry Pi 4 with 4GB of onboard RAM.
The board has 2 × micro-HDMI ports (up to 4kp60 supported), a 2-lane MIPI DSI display port, a 2-lane MIPI CSI camera port, a Micro-SD card slot for loading the operating system, and data storage 5V DC via USB-C connector, 5V DC via GPIO header. 2.4 GHz and 5.0 GHz IEEE 802.11ac wireless, Bluetooth 5.0, BLE Gigabit Ethernet and for the memory.

5. Scoring
We will evaluate the submitted algorithm with the scoring metric that evaluates the comprehensive performances in terms of detection performances and practical performances. It is defined as follows:
For detection performances,
- Overall Accuracy: we will compute the accuracy of the classification work generated by the submitted algorithm on the testing dataset. It is expected to discriminate as many black images as possible to avoid missed classification while achieving a high classification accuracy on whole test data.
For practical performances,
- Fairness Score: Based on the accuracy for each subgroup and Statistical Parity Difference (SPD) [4], the unfairness score U of a model N based on SPD, which is SPD (f ′N , Gi) for one subgroup, SPD (f ′N , Gi)=P(ˆY=1 ∣ A=minority)−P(ˆY=1 ∣ A=majority). For the minority group(the groups has the minimum samples), the SPD is 0. After that operation, we will have the table of the SPD for each group. For the unfairness score, it will be (0.2-∑∀gi∈G{|SPDi|}/N)/0.2. N is the the number of the subgroups that the dataset has.
-
Inference Latency: We will run 10 iterations to get the average latency L (in s) on Raspberry Pi 4 with 100 random selected images from testing dataset.
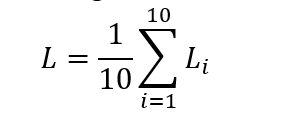 where L_i means the latency at i-th iteration.
The average inference latency L will be recorded The latency score will be normalized by
where L_i means the latency at i-th iteration.
The average inference latency L will be recorded The latency score will be normalized by
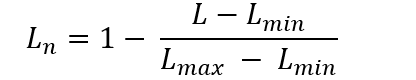 where L_min=0s, and L_max=100s.
where L_min=0s, and L_max=100s.
The final score will be calculated as follows:
Score = 1/3 × Acc + 1/3 × fairness score + 1/3 × L
6. References
[1 ]Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Advances in neural information processing systems, vol. 25, 2012.
[2] Sheng, Yi, et al. "The larger the fairer? small neural networks can achieve fairness for edge devices." Proceedings of the 59th ACM/IEEE Design Automation Conference. 2022.
[3] Platform. https://www.raspberrypi.com/for-home/.
[4] Unfairness. https://www.mathworks.com/help/risk/explore-fairness-metrics-for-credit-scoring-model.html.